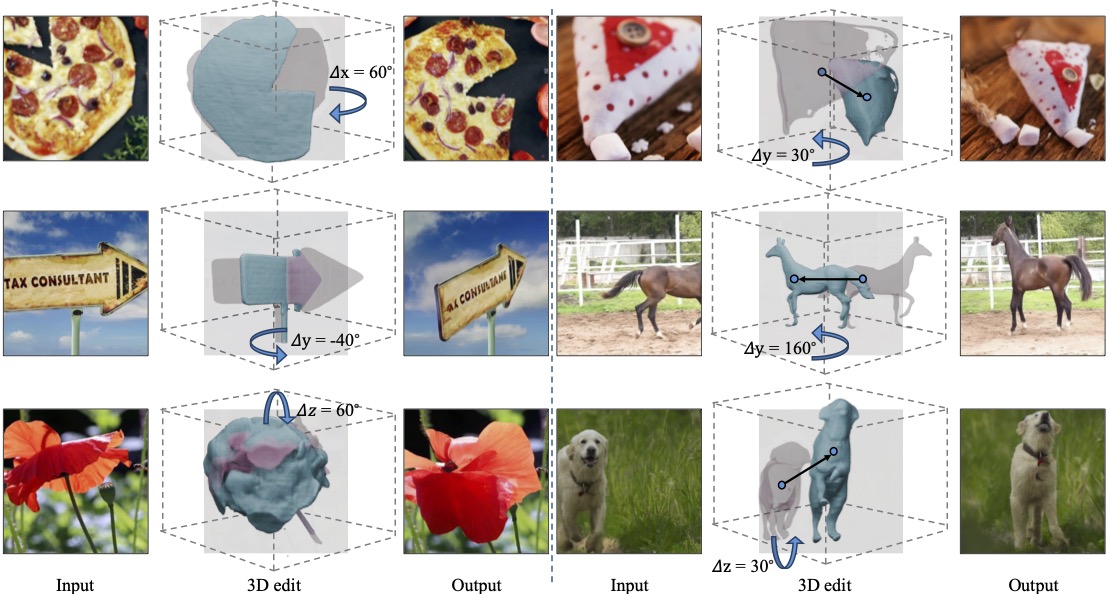
Despite significant advances in modeling image priors via diffusion models, 3D-aware image editing remains challenging, in part because the object is only specified via a single image. To tackle this challenge, we propose 3D- Fixup, a new framework for editing 2D images guided by learned 3D priors. The framework supports difficult editing situations such as object translation and 3D rotation. To achieve this, we leverage a training-based approach that harnesses the generative power of diffusion models. As video data naturally encodes real-world physical dynamics, we turn to video data for generating training data pairs, i.e., a source and a target frame. Rather than relying solely on a single trained model to infer transformations between source and target frames, we incorporate 3D guidance from an Image-to-3D model, which bridges this challenging task by explicitly projecting 2D information into 3D space. We design a data generation pipeline to ensure high-quality 3D guidance throughout training. Results show that by integrating these 3D priors, 3D-Fixup effectively supports complex, identity coherent 3D-aware edits, achieving high-quality results and advancing the application of diffusion models in realistic image manipulation.















Comparison with baselines. We compare several state of the art baselines with different kinds of conditions, such as 3D transforms, drags, inpainting masks, and text prompts. We can see that none of the baselines accurately follow the target 3D transform while preserving identity. Baselines that directly use 3D transforms suffer from a lack of good training data, and using other types of conditions makes it hard to unambiguously specify the 3D transform. |
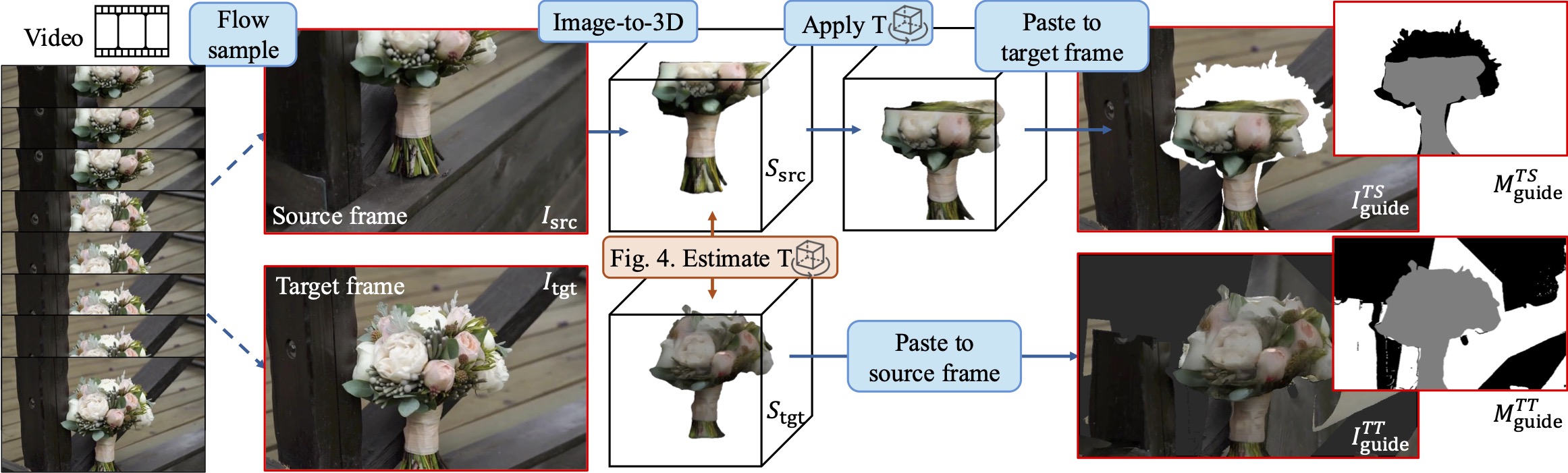
Given a video, we sample two frames, the source frame \( I_{\text{src}} \) src and the target frame \( I_{\text{tgt}} \), using optical flow as a cue: we discard videos where the flow indicates little motion through the entire clip. Using Image-to-3D methods, we reconstruct a mesh for the desired object for both frames. We then estimate the 3D transformation \(T\) (see Figure 4) between the source frame mesh and the target frame mesh. Availability of the transformation \(T\) enables two ways to create the training data: (1) in "Transform Source", we paste the rendering of the transformed source mesh onto the target frame; (2) in "Transform Target", we paste the rendering of the target mesh onto the source frame.

(Left) Overview of the training pipeline. We develop a conditional diffusion model for 3D-aware image editing.
It consists of two networks: \(f_\text{gen}\) and \(f_\text{detail}\) During training, given the inputs—target frame \(I_\text{tgt}\), 3D guidance
\(I_\text{guide}\), mask \(M_\text{guide}\), and detail features \(F_\text{t}\)--\(f_\text{gen}\) learns the reverse diffusion process to predict
the noise \(\epsilon\) and reconstruct \(I_\text{tgt}\).
To better preserve identity and fine-grained details from the source image \(I_\text{src}\), \(f_\text{detail}\) takes as input
the source image \(I_\text{src}\), its noisy counterpart \(I_\text{t}\) , and the mask \(M_\text{guide}\), and extracts
detail features \(F_\text{t}\). We apply cross-attention between \(F_\text{t}\) and the intermediate features of \(f_\text{gen}\)
to incorporate content and details from \(I_\text{src}\) during the reverse diffusion process.
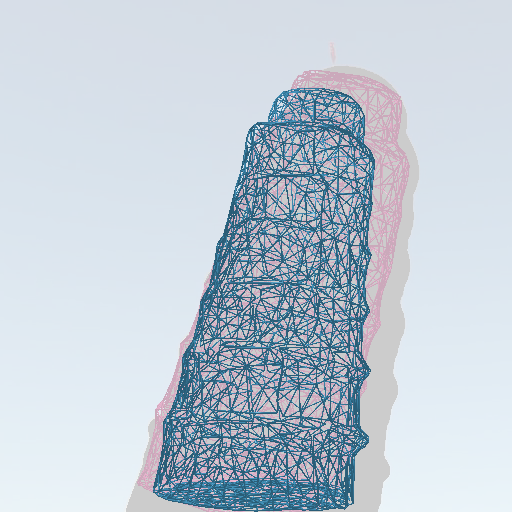
(Right) Inference. We assume editing instructions (possibly converted from text prompts) are in the form of 3D operations like rotation
and translation. Given a mask indicating the object to be edited, we first perform image-to-3D (InstantMesh [Xu et al. 2024])
to reconstruct the mesh. We then apply the user's desired 3D edit to obtain the 3D guidance. Here the 3D edit
is visualized as the transformation between original mesh (pink wire-frame) and
the edited mesh (cyan wire-frame). Finally, the model outputs the 3D aware editing result.
@inproceedings{cheng20253d,
author = {Yen-Chi Cheng and Krishna Kumar Singh and Jae Shin Yoon and Alexander Schwing and Liangyan Gui and Matheus Gadelha and Paul Guerrero and Nanxuan Zhao},
title = {{3D-Fixup: Advancing Photo Editing with 3D Priors}},
booktitle = {Proceedings of the SIGGRAPH Conference Papers},
year = {2025},
isbn = {979-8-4007-1540-2/2025/08},
publisher = {ACM},
doi = {10.1145/3721238.3730695},
}